What is Hadoop?

Apache Hadoop is an open-source software framework designed for distributed storage and processing of massive data sets across clusters of computers using simple programming models. It is built to scale from a single server to thousands of machines, each offering local computation and storage.
What is Apache Hadoop?
Developed by the Apache Software Foundation, Apache Hadoop was inspired by Google’s MapReduce and Google File System (GFS) papers. Today, it forms the backbone of many large-scale data processing platforms.
What is Hadoop Used For?
Hadoop is used for processing and storing Big Data—data sets that are too large or complex for traditional data-processing software. It is the foundation of most modern big data applications, enabling organizations to manage petabytes of structured, semi-structured, and unstructured data. Some common use cases include:
- Log Processing
- Recommendation Engines
- Data Warehousing
- Clickstream Analysis
- Machine Learning Pipelines
Hadoop Software Architecture
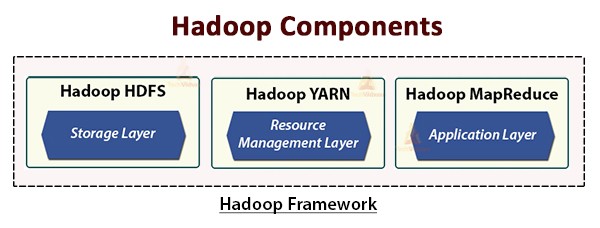
The Hadoop architecture consists of four primary modules:
- Hadoop Common: Core utilities and libraries.
- HDFS (Hadoop Distributed File System): Storage layer.
- YARN (Yet Another Resource Negotiator): Resource management.
- MapReduce: Processing engine.
What is is Hadoop Distributed File System (HDFS)?
HDFS in Hadoop? HDFS is a distributed file system in Hadoop designed to store large files reliably. It splits large files into blocks (typically 128MB or 256MB) and distributes them across nodes in a Hadoop cluster.
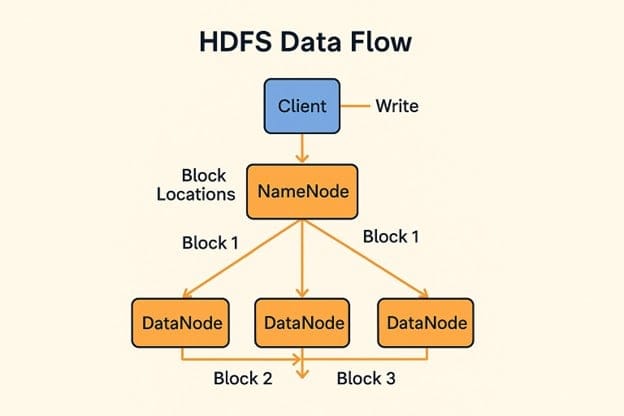
HDFS Data Flow Simplified:
A) Write Operation Steps:
- Client contacts the NameNode to create a file.
- NameNode splits the file into blocks and selects DataNodes to store them.
- Client writes each block directly to the first DataNode.
- That DataNode forwards the block to a second DataNode, which then forwards it to a third (this is called pipelined replication)
B) Read Operation Procedures Steps:
- Client requests file from NameNode.
- NameNode returns a list of DataNodes holding each block.
- Client reads blocks directly from the closest or fastest DataNodes.
C) Built-in Fault Tolerance Steps:
- Each block is replicated (usually 3 copies).
- If a DataNode fails, HDFS reads from another replica.
- Lost replicas are automatically restored by the NameNode.
What is a Hadoop Cluster?
A Hadoop cluster is a collection of computers (nodes) networked together to work as a single system. It includes:
- Master Node: NameNode (manages HDFS metadata) and ResourceManager (for YARN).
- Nodes: DataNode (stores actual data) and NodeManager (runs tasks).
What is is Hadoop MapReduce?
MapReduce is a core component of the Hadoop ecosystem used for processing large data sets. It involves two primary functions:
- Mapper: Breaks a task into smaller sub-tasks.
- Reducer: Aggregates the results.
What does Hadoop’s map procedure from its MapReduce program do? It filters and sorts of data into key-value pairs for further processing by the reducer.
What is Hive in Hadoop?
What is Hive and Hadoop? Hive is a data warehouse infrastructure built on top of Hadoop. It allows users to query data using HiveQL, a SQL-like language.
What is Hive in Hadoop? Hive simplifies querying, summarizing, and analyzing large-scale data. It translates HiveQL into MapReduce jobs under the hood.
What is Big Data and Hadoop?
What is Big Data Hadoop? It refers to using the Hadoop ecosystem to manage big data. The framework is built to handle the 3Vs of big data:
- Volume: Terabytes to petabytes.
- Velocity: Real-time or near-real-time.
- Variety: Structured, semi-structured, and unstructured.
How Does Hadoop Work?
- Data Ingestion: Using tools like Flume or Sqoop.
- Storage: Data is split and distributed using HDFS.
- Processing: Tasks are scheduled using YARN and executed using MapReduce, Hadoop Spark, or Tez.
- Querying: Via Hive, Pig, or Spark SQL.
What is Hadoop Spark?
Hadoop Spark, or more precisely Apache Spark, is a fast, in-memory data processing engine. While Hadoop uses disk-based MapReduce, Spark leverages in-memory processing, making it much faster for iterative algorithms like those in
Hadoop vs Spark: Spark is more efficient for real-time and batch processing, whereas Hadoop MapReduce is more disk-reliant but stable for batch jobs.

Hadoop Spark SQL and Architecture
Hadoop Spark SQL allows for querying data using SQL while leveraging Spark’s in-memory computation. Its architecture integrates with Hadoop through YARN and can be read from HDFS, Hive, and even external sources.
Is Hadoop a Database?
No, Hadoop is not a database. It’s a framework for distributed computing. Unlike traditional databases, Hadoop doesn’t support real-time querying or indexing by default. However, tools like Hive simulate database behavior on top of Hadoop.
How to Use -copyFromLocal in Hadoop?
The command hadoop fs -copyFromLocal <source> <destination> is used to copy files from the local file system to HDFS. The following is an example command:
hadoop fs -copyFromLocal /home/user/data.csv /user/hadoop/data.csv
Hadoop Ecosystems Components
- HDFS – Distributed storage
- MapReduce – Processing engine
- Hive – Data warehouse interface
- Pig – Data flow language
- Spark – In-memory processing
- Oozie – Workflow scheduler
- Flume – Log data ingestion
- Sqoop – Import/export from RDBMS
- YARN – Resource management

How to Learn Hadoop?
If you’re wondering how I can learn Hadoop, there are several great starting points:
- OMSA Learning Hadoop Spark: A practical course for beginners.
- Cloudera Hadoop Tutorials: Enterprise-level training.
- Apache Foundation Hadoop Docs: Official documentation.
- YouTube Tutorials: Visual and hands-on learning.
- Books: “Hadoop: The Definitive Guide” by Tom White.
You can start with a big data Hadoop and Spark project for absolute beginners Hadoop to get hands-on experience.
Installing Hadoop
The steps for Hadoop software installation:
- Download Hadoop from https://hadoop.apache.org/releases.html
- Extract and configure core-site.xml, hdfs-site.xml, and mapred-site.xml.
- Format HDFS with the following command: hdfs namenode -format
- Start services using the following command: start-dfs.sh && start-yarn.sh
- To check Hadoop versions, use the following commands: hadoop version
For Maven integration:
<property>
<name>hadoop.version</name>
<value>3.3.1</value>
</property>
Use mvn cli set hadoop version if working on Java or Scala-based apps.
Hadoop on ARM
Hadoop supports ARM architecture, especially with the rise of ARM-based servers and cloud computing. Custom builds are available for ARM64 processors.
Final Thoughts: What Does Hadoop Do?
So, what does Hadoop do? In essence, Hadoop will allow organizations to:
- Store large data sets efficiently.
- Process massive data in parallel.
- Query data with SQL-like interfaces.
- Build scalable big data applications.
It is not a traditional database but rather a distributed computing platform. Hadoop is a cornerstone of the Big Data revolution and continues to evolve through tools like Hadoop Spark, Hive, and YARN.
Bonus: Hadoop HADOOP_OPTS
Environment variable HADOOP_OPTS is used to pass custom JVM options to Hadoop processes, e.g., for logging or memory allocation by using the following command:
export HADOOP_OPTS=”-Djava.net.preferIPv4Stack=true”
References:
- Apache Hadoop
- Apache Spark™ – Unified Engine for large-scale data analytics
- Home – Apache Hive – Apache Software Foundation
- Apache Hadoop 3.4.1 – Apache Hadoop YARN
- Apache Hadoop 3.4.1 – HDFS Architecture
- Orders & Medals Society of America
- Simplilearn – YouTube
- Data analytics and AI platform: BigQuery | Google Cloud